
[机器学习]pytorch的安装和卷积神经网络
pytorch是由Facebook人工智能研究院基于Torch推出的可续计算包,支持GPU加速的张量计算;并且包含自动求导系统的深度神经网络。pytorch具有灵活性和易用性,是学习机器学习的良好框架之一。
如何开始
-
下载Annocanda,需要数十分钟,安装过程直接默认即可。官方下载页面
Annocanda是一个服务于数据科学的综合性工具库,其中包括Conda(包管理器),Jupyter Notebook(notebook形式python文件编辑器)等多种数据科学工具。详细介绍
-
安装完成后,使用
win+R,输入cmd,打开命令行输入界面,键入conda --version确认是否安装成功。如果出现无法识别的警告,请尝试配置环境变量为Annocanda的bin文件目录,如何配置PATH,请参考:PATH配置 - 确认conda安装成功后,使用以下指令创建虚拟环境,用于后期pytorch的学习:
conda create --name pytorch python=3.7此指令用于创建一个名为pytorch的虚拟环境,指定python版本为3.7,按照指示一步步确认即可
什么是虚拟环境?由于不同python程序需要的依赖版本不同,因此如果在同一个位置安装依赖容易混乱且易发生冲突,conda创建虚拟环境可以实现不同依赖配置之间的隔离,使得用户不必担心依赖冲突,而可以专注于开发,使用
conda env list可以查看所有的虚拟环境,其中base是默认的环境,安装自带。 -
创建完虚拟环境后,切换至新的虚拟环境,使用
conda activate pytorch,激活名为pytorch的虚拟环境此处可能报错要init,一般地,跟随指示即可,如无法解决,请自行检索。
- 在该虚拟环境下安装学习pytorch所需的主要配置,在cmd中键入以下指令:
conda install pytorch torchvision -c pytorch此处使用conda进行安装,其实也可以使用pip进行安装,-c是指下载的渠道(channel)指定为pytorch官方渠道
- 等待安装完毕后,在cmd中键入
python,进入命令行python脚本,测试是否成功安装配置:- 输入
import torch后,回车 - 输入
x = torch.rand(3),回车 - 输入
print(x),回车,此时应当可以正常打印包含三个随机数(0到1之间)的一维tensor张量 - 输入
torch.cuda.is_available(),回车 - 此时如果显示
True,代表你的GPU可以使用CUDA加速,如果是False,代表无法加速
- 输入
- 经过以上测试,如果按照预期输出,则表示pytorch配置成功!
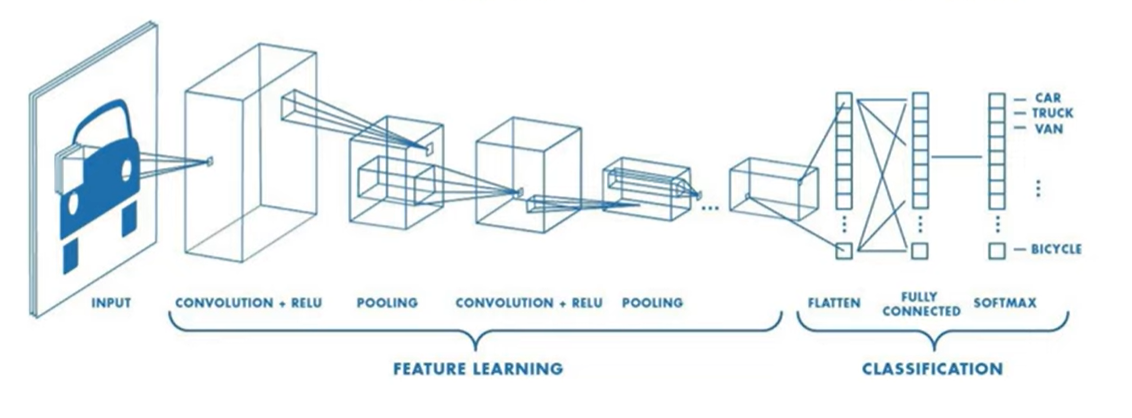
卷积神经网络
简要介绍
卷积神经网络主要用于图像、文本、等高维数据的分类问题。其中卷积(convolution)、池化(pooling)、填充(padding)过程是与普通神经网络不同之处,主要是用来降低维度,减少计算成本。
本篇博客中不关心其数学原理(主要是关心了也不懂),只关心如何应用和相关概念的解释。
训练过程
代码中的注释部分也比较重要,注意查看。例如计算图像大小如何变化那里,是Youtube博主讲了之后才有了清晰的理解。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
# Device configuration
# 根据是否有cuda决定计算模式
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# Hyper-parameters
# 超参数设置,一共有12个epoch,每次训练4个样本,学习率为0.001
num_epochs = 12
batch_size = 4
learning_rate = 0.001
# dataset has PILImage images of range [0, 1].
# We transform them to Tensors of normalized range [-1, 1]
# 数据集的图片是PILImage格式,范围是[0, 1],我们将其转换为张量,范围是[-1, 1]
transform = transforms.Compose(
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# CIFAR10: 60000 32x32 color images in 10 classes, with 6000 images per class
# 这个数据集有60000张32x32的彩色图片,分为10类,每类有6000张图片
train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)
test_dataset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size,
shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size,
shuffle=False)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
Files already downloaded and verified
Files already downloaded and verified
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# get some random training images
dataiter = iter(train_loader)
images, labels = next(dataiter)
# show images
# 随机显示一些图片,展示数据集
imshow(torchvision.utils.make_grid(images))

-
首先经过一个二维卷积过程,Conv2d函数的三个参数依次是:输入通道的个数、卷积产生的通道数、卷积核尺寸。
-
对于灰度图像,通道数目为1;对于彩色图像,通道数目一般为3:RGB。
-
卷积产生的通道数是由使用的卷积核个数决定的,由个人自己配置,只需要保证下一个卷积过程的输入和上一个卷积过程的输出一致即可。
-
卷积核的尺寸指的是多大的矩阵,如果只传入一个数字,代表正方形的卷积核。
-
padding是指填充边缘,使得卷积产生的图像符合预期大小而不是缩小太多。
-
-
然后再经过激活函数进入池化
-
然后再经过一层卷积,再带入激活函数,再池化
-
展开后使用全连接的线性层并带入激活函数
-
再使用一个全连接的线性层,并带入激活函数
-
最后输出一个全连接的线性层作用后的结果,不用带入激活函数,进入交叉熵损失函数进行评估。
class ConvNet(nn.Module): # 继承nn的基础模型
def __init__(self):
super(ConvNet, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5) # 输入通道是3,固定;输出是6,自己配置;卷积核大小,自己配置;步长默认是1;padding默认是0
self.pool = nn.MaxPool2d(2, 2) # 池化层,池化核大小是2,步长是2。是2×2的池化核。最大池化:取池化核中最大的那个像素
self.conv2 = nn.Conv2d(6, 16, 5) # 输入通道是6,与上个卷积核输出通道一致;输出是16,自己配置;卷积核大小,自己配置;步长默认是1;padding默认是0
self.fc1 = nn.Linear(16 * 5 * 5, 120) # 全连接层,输入是16*5*5,16是最后一层输出通道,5*5是图像大小,计算得出;输出是120,自己配置
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# -> n, 3, 32, 32
# 卷积->使用relu激活函数->池化
x = self.pool(F.relu(self.conv1(x))) # -> n, 6, 14, 14
# newsize = (W-F+2P)/S + 1 = (32-5+2*0)/ 1 + 1 = 28 其中W是输入大小(32×32),F是卷积核大小(5×5),P是padding,S是步长
# 池化后:newsize = (W-F) / S + 1 = (28 - 2)/2 + 1 = 14
x = self.pool(F.relu(self.conv2(x))) # -> n, 16, 5, 5
# newsize = (W-F+2P) / S + 1 = (14-5+2*0) / 1 + 1 = 10
# 池化后:newsize = (W-F) / S + 1 = (10 - 2) / 2 + 1 = 5
x = x.view(-1, 16 * 5 * 5) # -> n, 400
# x变成二维,第一维是自动配置,第二维是16*5*5
x = F.relu(self.fc1(x)) # -> n, 120
# 全连接->使用relu激活函数
x = F.relu(self.fc2(x)) # -> n, 84
# 最终不需要调用激活函数,因为在交叉熵损失函数中已经调用了softmax
x = self.fc3(x) # -> n, 10
return x
model = ConvNet().to(device)
criterion = nn.CrossEntropyLoss() # 标准,判据:交叉熵损失函数
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate) # 创建随机梯度下降优化器,优化model中的参数
n_total_steps = len(train_loader)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
# origin shape: [4, 3, 32, 32] = 4, 3, 1024
# input_layer: 3 input channels, 6 output channels, 5 kernel size
images = images.to(device)
labels = labels.to(device)
# Forward pass
outputs = model(images)
loss = criterion(outputs, labels) # 计算输出与标签之间的损失
# Backward and optimize
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 2000 == 0:
print (f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{n_total_steps}], Loss: {loss.item():.4f}')
print('Finished Training')
PATH = './cnn.pth'
torch.save(model.state_dict(), PATH)
Epoch [1/12], Step [2000/12500], Loss: 2.2721
Epoch [1/12], Step [4000/12500], Loss: 2.2939
Epoch [1/12], Step [6000/12500], Loss: 2.2933
Epoch [1/12], Step [8000/12500], Loss: 2.2101
Epoch [1/12], Step [10000/12500], Loss: 2.1012
Epoch [1/12], Step [12000/12500], Loss: 2.1055
... ...
Epoch [11/12], Step [2000/12500], Loss: 0.4531
Epoch [11/12], Step [4000/12500], Loss: 0.7385
Epoch [11/12], Step [6000/12500], Loss: 1.1635
Epoch [11/12], Step [8000/12500], Loss: 1.2126
Epoch [11/12], Step [10000/12500], Loss: 1.0320
Epoch [11/12], Step [12000/12500], Loss: 0.8422
Epoch [12/12], Step [2000/12500], Loss: 0.4254
Epoch [12/12], Step [4000/12500], Loss: 0.9570
Epoch [12/12], Step [6000/12500], Loss: 0.8855
Epoch [12/12], Step [8000/12500], Loss: 1.3658
Epoch [12/12], Step [10000/12500], Loss: 0.7077
Epoch [12/12], Step [12000/12500], Loss: 1.1257
Finished Training
with torch.no_grad(): # 上下文管理器,关闭对于梯度的计算,在评估模型的时候并不需要更新参数
n_correct = 0
n_samples = 0
n_class_correct = [0 for i in range(10)]
n_class_samples = [0 for i in range(10)]
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
# max returns (value ,index)
_, predicted = torch.max(outputs, 1)
n_samples += labels.size(0)
n_correct += (predicted == labels).sum().item()
for i in range(batch_size):
label = labels[i]
pred = predicted[i]
if (label == pred):
n_class_correct[label] += 1
n_class_samples[label] += 1
acc = 100.0 * n_correct / n_samples
print(f'Accuracy of the network: {acc} %')
for i in range(10):
acc = 100.0 * n_class_correct[i] / n_class_samples[i]
print(f'Accuracy of {classes[i]}: {acc} %')
Accuracy of the network: 59.84 %
Accuracy of plane: 52.3 %
Accuracy of car: 73.4 %
Accuracy of bird: 41.4 %
Accuracy of cat: 27.1 %
Accuracy of deer: 57.0 %
Accuracy of dog: 59.7 %
Accuracy of frog: 76.9 %
Accuracy of horse: 61.9 %
Accuracy of ship: 83.8 %
Accuracy of truck: 64.9 %
Epoch = 5
Accuracy of the network: 48.21 %
Accuracy of plane: 47.0 %
Accuracy of car: 56.3 %
Accuracy of bird: 29.1 %
Accuracy of cat: 45.5 %
Accuracy of deer: 21.5 %
Accuracy of dog: 27.4 %
Accuracy of frog: 66.7 %
Accuracy of horse: 57.3 %
Accuracy of ship: 73.3 %
Accuracy of truck: 58.0 %
Epoch = 12
Accuracy of the network: 59.84 %
Accuracy of plane: 52.3 %
Accuracy of car: 73.4 %
Accuracy of bird: 41.4 %
Accuracy of cat: 27.1 %
Accuracy of deer: 57.0 %
Accuracy of dog: 59.7 %
Accuracy of frog: 76.9 %
Accuracy of horse: 61.9 %
Accuracy of ship: 83.8 %
Accuracy of truck: 64.9 %
Epoch = 24
Accuracy of the network: 63.98 %
Accuracy of plane: 72.9 %
Accuracy of car: 68.9 %
Accuracy of bird: 44.2 %
Accuracy of cat: 36.4 %
Accuracy of deer: 63.1 %
Accuracy of dog: 53.0 %
Accuracy of frog: 81.7 %
Accuracy of horse: 71.5 %
Accuracy of ship: 74.6 %
Accuracy of truck: 73.5 %\
可以看到随着轮次的提升,我们模型的精度也有相应的提升。但是由于本电脑没有英伟达显卡不支持cuda加速,所以计算耗时太久,调参过程就到此为止吧。
batch_size 也是可以适当提升的,但是不宜过高,否则一是内存占用吃不消,二是不利于跳出网络的局部极小点
以下有可供参考的cnn视频链接,这位博主是我觉得在应用层讲的十分清晰明了的一位,点击Direct Link即可跳转。

爱来自:SakuraMarble
转载或引用请标注来源,欢迎评论!